
개요
안녕하세요 dev_writer입니다.
오늘은 지난번 당근 ML 밋업에서 발표한 LLM을 프로덕션에 적용하며 배운 것들을 주제로 어떤 내용이 들어있는지를 정리해보고자 합니다.
제 글을 이전부터 봐오신 분들은 Spring AI에 대해서 제가 공부를 하고 있는 것을 아실 텐데요. Spring AI를 이용하여 학교에서 캡스톤 프로젝트를 한 뒤 동상을 얻는 등 좋은 성과가 있었습니다.
하지만 마주쳤던 문제점들이 있어서 이번 방학부터 진행할 부트캠프에서도 이 주제를 기반으로 다시 만들어보려고 하는데요, 접했던 문제 중 하나인 LLM이 원치 않는 데이터를 반환해 주는 문제를 어떻게 해결할 수 있을까에 대한 고민이 있어 위 세션을 들어보고 정리하였습니다.
당근에서의 LLM 사용 예
당근에서는 LLM을 어떻게 사용하고 있을까요? 당근에서는 중고거래, 동네생활, 모임 등에서 LLM을 사용하고 있습니다.

일례로 동내생활 서비스에서는 작성자가 해시태그를 작성하지 않았다면, 작성한 내용을 기반으로 LLM이 해시태그를 추천해 주는 기능을 적용하였습니다.
실시간 LLM 파이프라인

당근에서는 LLM이 필요한 서비스 (게시글 등)에서 실시간 작업을 위해 특정 기능 (ex: 게시글 작성)이 발생할 때마다 Kafka로 흘러들어오는 이벤트를 받아 미리 지정한 LLM 예측을 수행, 결과를 다시 Kafka 토픽과 빅쿼리로 내보낼 수 있도록 구성하고 있습니다.
추가적으로 다른 서비스에서 LLM을 적용하더라도 해당 파이프라인을 이용하면 손쉽게 LLM을 적용할 수 있도록 설계한 점이 인상 깊었습니다. 백엔드 개발자를 준비하는 저로서는 이름만 듣게 되었던 Kafka가 이런 상황에서 쓰일 수 있구나를 알게 되었습니다.
당근에서 제공하는 LLM 적용 팁
1. Prompts Matter
프롬프트 (Prompt, 특정 작업을 수행하도록 생성형 AI에 요청하는 자연어 텍스트 - AWS 문서)는 LLM의 품질을 결정하는 가장 큰 핵심 요소라고 할 수 있습니다.
대표적으로 제가 자주 사용하는 패턴 중 하나로는 ChatGPT에게 "너는 20년 이상의 경력을 가진 xxx 직군의 마스터야.."라는 등의 역할 (Role)을 부여하고 있기도 합니다.
당근에서도 이러한 문제를 겪었고, 프롬프트를 잘 작성하는 것이 중요한 것을 강조했습니다.
2. 반복된 실험과 평가가 핵심
좋은 프롬프트를 만들기 위해서는 반복적인 실험과 평가가 중요합니다.
이를 위해서는 평가 데이터셋을 마련하고, 자동화 된 배치 평가 파이프라인을 마련해야 합니다.
예시로 위의 당근 사례를 보면 동네생활 게시글들을 평가 전용들로 데이터를 만들어두고, 이러한 데이터들을 넣었을 때 예상했던 기대 출력값 (JSON 등)등이 나오는지 항상 확인해야 합니다.
더 구체적으로는 평가 데이터셋에 중요한 엣지 케이스를 포함하고 보완하기, 자동화된 배치 평가 파이프라인에서는 Error / Invalid format Rate를 측정하는 등의 방법이 있습니다.
이 부분을 보면서는 실제 Spring AI에서 작성된 테스트 코드 부분이 생각났습니다. Spring AI 모듈을 다운로드하고 실행해 보면 실제 ChatGPT를 호출하여 정상적으로 출력이 되는지 등의 과정을 검증하는 것이 있음을 보실 수 있습니다.
또는 도메인 전문가의 정성 평가도 활용할 수 있는데요. 만약 스타일에 맞는 옷 종류를 생성해 달라는 요청이 있고 이를 LLM으로 만든다 하더라도 개발자가 의류 도메인에 대해 제대로 된 지식이 없다면 LLM이 제대로 결과를 만들어줬는지에 대해 모호성이 있을 것입니다.

당근에서는 크게 배치 평가와 프로덕션에 대해 두 가지의 파이프라인을 나누어 구성했습니다.
배치 평가에서는 평가 데이터셋에 배치 평가와 프롬프트 개선을 반복하며, 프로덕션 파이프라인에서는 온라인 지표 모니터링, 샘플링 분석 등으로 끊임없이 프롬프트를 최대한 개선시키고자 하는 설계가 보였습니다. 이는 실제 프로덕션에서는 이전에 평가 단계에서 보지 못했던 예외 케이스들을 많이 접할 수 있기 때문입니다.
3. 좋은 프롬프트를 만드는 노하우를 체계화하기
위에서 설명했듯이 언제든지 LLM을 이용하여 기능을 개발해야 하는 상황이 생길 수 있습니다. 그리고 그 기능은 이전에 LLM 기능 개발을 했던 사람이 아닌, 다른 사람이 프롬프트를 만들 수 있기도 하죠.
시행착오를 겪은 뒤 만들게 되었던 프롬프트를 회사 내에서 다른 사람들도 공유하여 비슷한 품질의 성능을 낼 수 있도록 당근에서는 LLM 노하우를 서로 공유하는 문화를 가지고 있다고 합니다.
만약 제가 여러 명의 개발자와 함께 LLM 서비스를 만든다면, 항상 첫 프롬프트로 역할 부여를 하는 것을 체계화하는 등으로 모방할 수 있을 것 같습니다.
4. 구분자로 구조를 명확하게
프롬프트의 각 구성요소를 구분자로 명확하게 구조화하면 모델이 더욱 이해하기 좋고 성능을 높일 수 있습니다.
당근에서 권장하는 방식은 XML, Markdown 등의 포맷을 적용하는 것이었습니다.
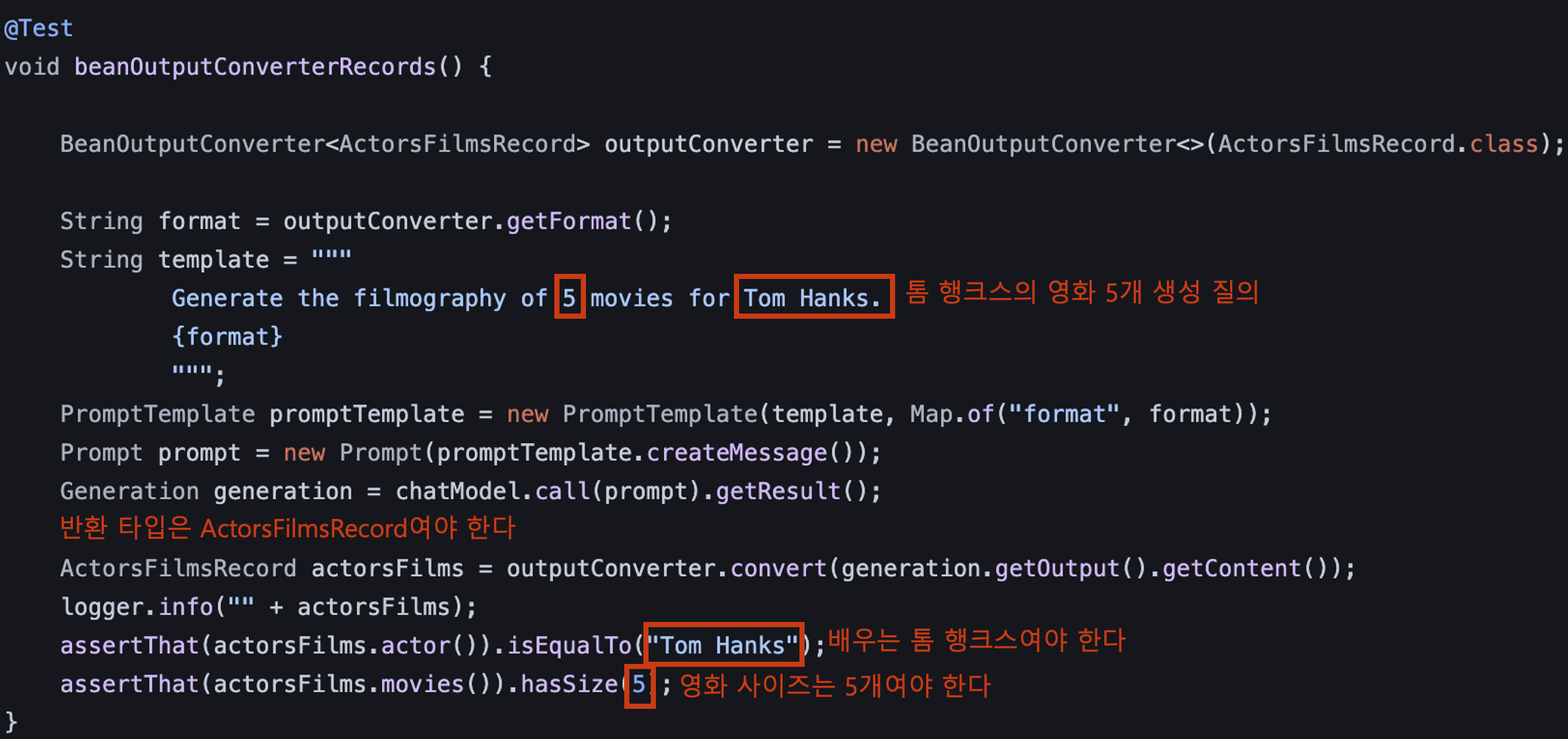
Spring AI에서는 PromptTemplate이 그 역할을 대체할 수 있을 것으로 보입니다. (톰 행크스 예시 사진 참고)
5. 요구사항을 구체화하기
구체적인 요구사항이 없으면 원하는 결과를 얻기 어렵습니다. 세부 사항을 명확하고 구체적으로 지시해야 합니다.
예시로 제가 학교에서 진행한 프로젝트에서는 무조건 JSON 형식으로만 반환해야 한다는 규칙을 넣기도 했습니다.
여기서 또 반복 평가가 중요한 이유가 나옵니다. 처음에는 이 정도까지만 요구사항을 작성하면 되겠지라고 넣었다가, 반복 평가를 통해 요구사항을 구체화하고 평가 데이터를 강화하게 되는 계기가 되기도 하기 때문입니다.

6. 예시 활용하기
LLM은 주어진 예시가 있을 때 더 좋은 성능을 낼 수 있습니다. JSON의 예시를 보여주는 등의 작업을 할 수 있습니다.
그렇지만 예시를 너무 구체적으로 많이 주게 되면 성능이 떨어져, 처리할 입력이 예시와 비슷하거나 잘 모르겠을 때 예시를 그대로 사용하는 경향이 있기도 합니다.
실제로 학교 프로젝트에서는 이 점을 몰라 계속 반복적으로 예시 데이터만을 이용하는 것을 볼 수 있었습니다.
이에 대해 당근에서는 지시 사항을 이해하고 출력 형식을 설명하기 위한 1~2개의 예시만 제한적으로 사용하는 것을 추천하고 있습니다.
7. 생각하고 말하게 하기
한 번에 바로 결과만 생성하는 것보다 단계별로 사고 과정을 작성하도록 하면 더 좋은 결과를 얻을 수 있고, 복잡한 작업일수록 더욱 효과가 나타납니다.
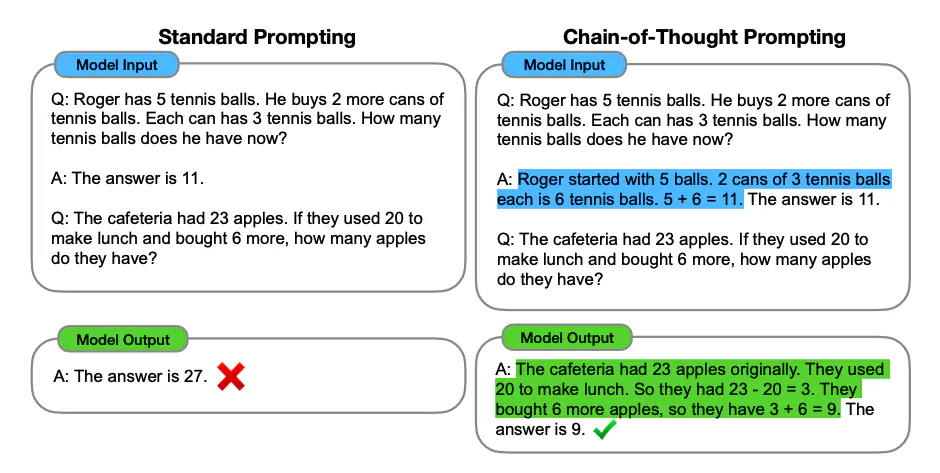
이를 생각의 사슬 (Chain of Thought, CoT) 프롬프팅이라고 하는데요. 위 예시를 보면 예시로 넣어준 답변이 좌측에서는 바로 답을 내리고, 우측에서는 답을 얻은 이유를 기술하게끔 작성했습니다. 그 결과 모델이 새로운 질문을 받았을 때 답을 얻은 이유의 예시처럼 생각을 하게끔 내린 답변이 더 정확히 되었음을 보실 수 있습니다.
여기서 더 강화시킨다면 반대되는 개념으로 CCOT (Contrasive Chain-of-Thought)를 적용할 수 있는데, 틀린 답변에 대해서도 예시를 준 경우에 해당합니다.

이 외에도 Rephrase and Respond, Take a Step Back 등의 기법을 적용할 수 있습니다.
당근에서는 응답을 낸 이유 (reason)를 먼저 나오게 한 뒤 사용자의 성별과 연령을 추정하는 방법, 요약을 먼저 한 다음 핵심 단어를 분류하는 방법 등으로 적용했습니다.
8. Pseudo-Code로 지시하기
많은 LLM들이 코드에 대한 학습을 많이 수행했기 때문에 코드 형태로 작성된 문서에 대한 이해력이 높습니다.
복잡한 조건이나 반복이 필요한 지시사항이 있다면 자연어로 길게 설명하는 것보다 간략한 코드 형태로 지시하는 경우 더 잘하기도 합니다.
예를 들어 학교 프로젝트에서는 프론트엔드 분이 필요하신 TypeScript의 형태로 구조를 넣어두기도 했습니다.
9. 지시사항과 사용자 입력의 순서도 영향을 준다
컨텍스트로 사용하는 문서의 길이가 긴 경우 지시사항과 사용자 입력을 앞쪽에 두면 컨텍스트로 인해 잊히는 경향이 있음을 발견했다고 합니다. 따라서 컨텍스트가 길다면, 지시사항과 사용자 입력을 뒤쪽에 두는 것이 유리합니다.
이 부분은 미처 알지 못했던 내용인데요, 생성했던 프롬프트를 봤을 때 매우 양이 길어 JSON으로 출력하라는 지시사항을 무시한 적이 있었습니다. 다시 프로젝트를 할 때는 이러한 사실을 꼭 잊지 말아야겠다는 생각이 들었습니다.
10. field 이름도 영향을 준다
생성하려는 field의 이름도 결과에 영향을 줍니다. 혼란을 주지 않도록 지시사항을 구체적으로 주고, 지시에 맞는 이름을 지정하는 게 좋습니다.

이를 방지하기 위해서는 지시사항을 최대한 구체적으로 주고, 적합한 필드 이름을 넣어보고 결괏값들을 비교해 보는 방식이 권장됩니다.
11. 잘 모르면 지어낸다 (hallucination 문제)
많은 기업에서 LLM을 선뜻 도입하기 어려운 이유 중 하나로는 hallucination (환각) 문제가 있습니다.
아래 예시에서도 데이터가 없는 경우에는 스포츠/레저를 반환하는 등 전혀 원하지 않는 응답을 반환한 것을 볼 수 있는데요, 이런 경우에는 주어진 목록에 없는 경우에는 없음으로 출력하라는 식으로 교정했습니다.

12. 출력 형식 제어하기
출력 형식 (주로 JSON)을 반드시 지켜야 한다는 식의 프롬프트를 넣었긴 했지만, 간혹 구조는 지켰지만 각 필드 값의 형식이 원하는 형태에서 벗어나는 경우도 있습니다.
이를 대비하여 값의 형식을 검증하고 후처리 하는 로직을 파이프라인에 미리 추가하는 것을 추천하고 있습니다.

13. 모델 선택하기
LLM은 다양한 모델들이 있습니다. 하나의 모델로 모든 사례에 적용하기보다는 필요한 성능, 비용, 입력의 길이, 동시 요청량 등을 고려해서 적합한 모델을 선택하는 것이 좋습니다.
use case에 따라 모델을 나눌 수도 있고, 입력에 따라 모델을 나눌 수도 있겠죠.
무작정 ChatGPT를 사용하기보다는 왜 ChatGPT를 도입하기 좋을지에 대한 고민이 필요하겠다는 생각이 들었습니다.
14. 실패를 대비하기
LLM은 API를 이용하여 모델을 사용합니다.
그러나 OpenAI에서 ChatGPT 사용 장애가 발생했던 것처럼, 충분히 LLM API도 프로덕션 환경에서 장애가 발생할 수 있습니다.
이때 크게 두 가지 해결법이 있습니다.
- Model Fall-back
- 실시간 서비스인 경우 다른 모델로 대체합니다.
- 동일한 프롬프트를 사용해도 모델에 따라 품질이 다를 수 있습니다.
- Data back fill
- 비동기로 데이터 처리를 하는 경우 사용합니다.
- 실패한 건에 대해 장애 이후 재처리할 수 있도록 합니다.
비동기로 데이터 처리를 하는 경우는 아직 접하지 못했는데, 실시간 서비스일 때 ChatGPT가 장애가 발생한다면 Gemini 등의 다른 모델로 교체할 수 있을 것으로 보입니다. 다만 다른 모델인 만큼, 동일한 프롬프트를 사용해도 품질이 달라질 수 있겠다는 게 위험 요소로 생각됩니다.
15. 모델 수명 고려하기
LLM은 계속해서 새로운 버전으로 업데이트됩니다. 그 말은 기존 버전은 제한된 수명을 가진다는 뜻입니다.
Auto-update 모델을 사용하면 모르는 사이 모델이 변경될 수 있기에, 프로덕션에서는 꼭 버전을 지정해서 사용하는 것을 추천하고 있습니다.
16. 사용량 고려하기
LLM API는 사용량 제한이 있습니다. 사용자가 백만 명 정도 되는 서비스에서 전부 ChatGPT API를 호출하도록 하면 사용량이 초과될 확률이 높습니다. 이는 곧 모든 파이프라인의 장애로 이어질 수도 있습니다.
관련 해결법으로는 아래가 있습니다.
- 프로덕션 서비스 계정의 사용량이 제한에 가깝지 않은지 모니터링하기
- 파이프라인 별로 사용량을 모니터링하고 내부적인 사용량 제한을 설정하기
- 파이프라인 별 서비스 계정을 분리하기
OpenAI에서 알려주는 Rate Limit을 참고하면 제한량이 있음을 볼 수 있습니다.

17. 서비스와 기능의 성공에 집중하기
결국 LLM을 도입하려는 이유는 비즈니스 목표 때문입니다. 그렇기 때문에 프로덕션에서 성공을 측정하는 지표를 관찰하고 집중하며, 배치 평가에서 보지 못했던 오류와 예외를 모니터링하고 평가 데이터에 추가해서 반복 개선하는 과정이 필요합니다.

요약 (by 당근)
당근에서 소개한 내용을 요약하면 다음과 같습니다.
- 반복적인 실험과 평가를 빠르게 하는 것이 핵심
- 좋은 프롬프트에 대한 노하우를 체계화하고 가이드라인 만들기
- 프롬프트의 프로덕션 배포는 끝이 아닌 시작. 서비스와 기능의 성공에 집중하고 지속적으로 개선하기
개인적으로 느낀 점
개인적으로 프로젝트를 하면서 프롬프트를 최대한 세부적으로 교정해야 서비스의 품질이 높아질 수 있음을 시연할 때를 통해 알게 되었습니다. 사람들 앞에서 시연했었을 때 데이터가 null 등의 원치 않는 데이터로 나오게 되어 곤란했던 상황이 있었기도 했습니다. 하물며 개발한 서비스가 만약 수백만의 이용자가 사용하고 있던 서비스였다면 어땠을까요? 그 순간 서비스의 신뢰도는 바닥을 찍을 것입니다.
물론 저는 백엔드 개발자를 준비하는 입장으로서, 프롬프트 엔지니어링은 ML 직군에 계신 분들과 더 밀접한 연관이 있다고 생각합니다. 하지만 결국 서비스를 만들기 위해서는 ML 직군 분들과 의사소통이 제대로 되어야 하고, 지금과 같은 소규모 프로젝트를 할 때에는 제가 ML 영역의 일도 해야 할 일이 있을 수 있기 때문에 위와 같은 세미나들을 계속해서 보고 공부하는 훈련이 필요하다고 생각했습니다.
대표적으로 얻어간 것은 반복된 실험과 평가, 프롬프트 교정법이었습니다.
테스트 코드를 작성할 때는 비용이 아깝기도 하고 단순히 Mocking만 하면 되지 않을까라는 생각을 했었는데, 지금 와서 보니 안일한 생각이었다는 것을 알게 되었습니다. 서비스의 품질이 높아지기 위해서는, 사용자들이 안전하게 사용할 수 있게 하기 위해서는 테스트 과정에서도 실제로 LLM API를 호출하여 의도대로 흘러가는지를 봐야 하고, 프로덕션 환경에서도 계속해서 모니터링이 필요하기 때문입니다.
더불어 프롬프트를 어떻게 작성하느냐에 따라 결과가 천차만별로 달라질 수 있다는 사실을 다시 한번 느끼게 되었습니다.
Reference
'세미나' 카테고리의 다른 글
| [세미나] 240516 실용주의 기술 블로그 글쓰기 devocean 후기 (3) | 2024.05.20 |
|---|