안녕하세요 dev_writer입니다. 원래 DB 설계 과정에서의 고민을 바로 올리려 하였으나, 추가적인 고민점들이 여러 개 생겨 2번째 API 설계 과정 고민 글을 올리게 되었습니다.
1. DELETE 행위는 200 OK가 맞을까 204 No Content가 맞을까?
프로젝트에서는 DELETE API와 관련된 작업이 존재하는데, 로그아웃과 음식 삭제가 그 예입니다.
- 로그아웃은 레디스에서 보관한 refresh token을 삭제하는 방식으로 이루어집니다.
- 음식 삭제는 음식의 상태를 soft delete화 하여, deleted_at을 현재 시각으로 업데이트합니다. 일부분인 deleted_at이 업데이트되는 것이기에 PATCH로도 쓸 수 있지만, API의 의도를 명확히 하기 위해 DELETE를 사용하기로 결정하였습니다.
이때 삭제 행위에 대해서는 크게 200 OK와 204 No Content 두 가지를 쓸 수 있는데요, 어떤 때 200 OK를 쓰고 어떤 때 204 No Content를 쓰는 게 원래의 의도 상 더 알맞은 것일까요? MDN 공식 문서를 보겠습니다.
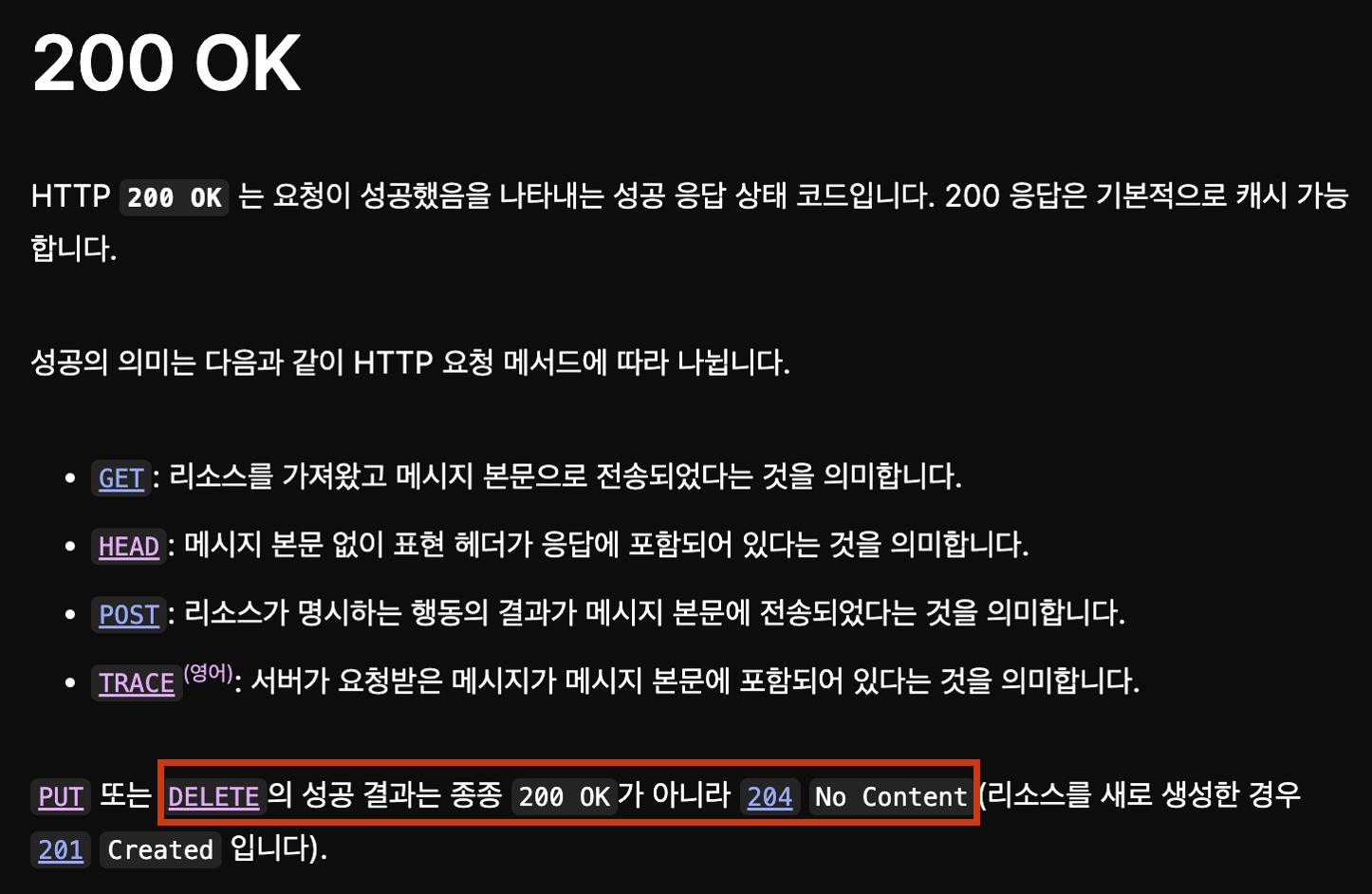
MDN에서는 DELETE의 작업 성공 결과로 200 OK를 쓸 수도 있지만 종종 204 No Content를 쓸 수 있다고 되어 있습니다.
그리고 204 No Content의 문서에서는 성공된 상태를 내포함을 의미하고 있습니다.

관련된 스택오버플로우 질문을 보면 더 명확히 답을 얻을 수 있습니다.

- HTTP 200 OK: 성공적인 HTTP 요청에 대한 응답의 표준입니다. 실제 응답은 요청 메서드의 사용에 따라 다릅니다.
- HTTP 204 No Content: 서버가 성공적으로 요청을 수행하였지만, 아무 내용도 전달하지 않습니다.
이 설명들을 토대로 저희 서비스를 볼 때, 본 프로젝트는 삭제 시 아무런 데이터도 응답하지 않는 것으로 설계하였기 때문에 기존 200 OK보다는 204 No Content를 이용하기로 하였습니다. (물론, 삭제할 때 어떤 특정 값을 반환하기로 했다면 200 OK가 적합하다고 생각합니다!)
2. PresignedURL을 공통화하자 (설계의 차이)
이전 글에서 음식 목록을 조회할 때 API를 하나로 통합하는 방식을 쓰기로 했었는데, PresignedURL을 얻는 API들도 통합하는 게 좋겠다는 생각이 들었습니다.
기존에는 아래 두 가지가 있었습니다.
- 프로필 사진 업로드용 PresignedURL 요청 GET /api/members/me/info/presigned-url
- 음식 사진 업로드용 PresignedURL 요청 GET /api/foods/presigned-url
원래 의도는 각 도메인에 따른 presigned url을 생성하는 것임을 명확히 하기 위해 이렇게 구분했었습니다.
그런데 한편으로는 이러한 생각도 들었습니다.
- 다른 도메인이 생기고 사진 (or 파일) 업로드가 발생할 때 쓸 저장소는 S3으로 동일하다.
- PresignedURL 생성의 응답 (presigned url 및 파일이 보관될 url)은 도메인에 상관없이 모두 같다.
- PresignedURL을 생성할 때 활용되는 동적 값은 회원의 id (or 닉네임) 뿐이다.
이러한 이유 때문에, 이전에 조회 API를 통합한 사례처럼 쿼리 파라미터로 구분하기로 했습니다. 오히려 그 방식이 구글 검색에서의 예시와 비슷하다고 생각이 들었습니다. (https://www.google.co.kr/search?q={값})처럼, "<어떤 도메인>에 대한 presigned url을 조회해 줘"와 같은 의미로 정의할 수 있기 때문입니다. (그리고 가능한 쿼리 파라미터 목록은 어떤 게 있는지도 API 명세서에 포함시키면 될 것입니다.)
또 S3으로부터 PresignedURL을 생성하도록 하는 S3PresignedUrlManager 인터페이스를 둔다면, 각 도메인의 서비스는 이 인터페이스를 의존하지 않아도 됩니다. (더불어 API 생성을 줄일 수 있습니다.)
// 기존
GET /api/members/me/info/presigned-url
GET /api/foods/presigned-url
// 응답
{
"presigned_url": "https://sample.s3.northeast-2.amazonaws.com/...",
"image_url": "https://sample.s3.northeast-2.amazonaws.com/..."
}
// 수정 이후
GET /api/presigned-url?goal={value} // value는 profile, food 등이 들어갈 수 있음
이렇게 하면 로그인 한 회원의 id와 value를 이용하여 S3 패키지를 정의할 수 있겠다는 생각이 들었습니다.
3. ChatGPT에게 질의할 때 사용되는 쿼리 파라미터의 값 고민
이전 글에서 잠깐 설명드렸던 ChatGPT에게 플랜을 검색하는 API는 아래와 같이 설계했었습니다.
// 요청
GET /api/plans/predict?food_id=1 // food_id는 음식 DB의 id를 의미
// 응답
{
"plans": [
{
"type" : "헬스",
"exercises" : [
{
"name" : "프론트 레이즈",
"repeat" : 10,
"expect" : 300,
"size" : 3,
"weight" : 3
},
{
"name" : "사이드 레터럴 레이즈",
"repeat" : 10,
"expect" : 200,
"size" : 3,
"weight" : 4
}
]
},
{
"type" : "스포츠",
"exercises" : {
"name" : "복싱",
"expect" : 500,
"time" : 3600
}
}
]
}
기존에는 음식의 DB id를 쿼리 파라미터로 넘기게 함으로써 DB에 저장된 음식을 조회한 뒤, 해당 음식이 가진 칼로리를 가져와서 로그인 한 회원의 정보와 함께 ChatGPT에게 넘겨주는 방식을 생각했었습니다. 이는 음식을 만들었으니 회원이 만든 음식의 id를 입력하면 회원의 정보와 음식의 정보 (칼로리)를 함께 조합하는 것이기 때문에 권한 측면 (ex: 음식 1과 음식 2가 있으나 현재 로그인 한 회원은 음식 1만 만들었을 때 음식 2에 대한 id를 넘기면 예외를 던지는 등)에서 자연스러운 흐름이라고 생각했었기 때문입니다.
그런데 한편으로는 이런 생각도 들었습니다.
- 음식의 칼로리를 제외하고 음식의 다른 정보 (ex: 탄수화물, 단백질, 지방)가 서비스의 원래 의도를 구현하기 위해 필요한가?
- ChatGPT에게 넘기는 정보는 음식의 칼로리와 회원의 정보인데, 회원의 정보는 로그인 검증으로 구분할 수 있다. 그런데 음식도 그래야 할까? 음식을 조회한 뒤 사용되는 정보가 칼로리뿐이라면, 칼로리를 쿼리 파라미터로 전달하면 끝내도 되지 않을까?
- 음식을 조회하는 과정을 제거함으로써 불필요한 DB 접속에 따른 응답 저하를 줄일 수 있을 것 같다. 또한 플랜 생성을 맡은 서비스에서 음식을 조회하는 음식 리포지터리를 의존할 필요도 없게 된다.
불필요한 DB 접속에 따른 응답을 제거할 수 없다는 점, 플랜 생성 서비스에서 음식 조회 리포지터리를 의존하지 않아도 된다는 점 때문에 아래와 같이 칼로리를 쿼리 파라미터로 직접 입력받도록 변경하였습니다. (/api/plans/predict?kcal=374.24 이런 식으로 말이죠.)
한편으로는 음식에서는 플랜의 상태 (WAITING, CREATED, DONE)를 가지고 있기 때문에 음식을 조회해야 하는 것 아닌가라는 생각이 들었으나, 본 API는 플랜 "검색"의 API이며 플랜을 생성함에 따라 음식이 가진 플랜의 상태를 변경하는 행위는 플랜 "생성" API에서 음식 id를 Request body로 전달하기 때문에 해당 API에서 이벤트로 처리하면 되겠다는 결론을 내렸습니다.
4. 회원 정보 등록/수정의 API를 각각 모두 분리하자 + id 반환 방식과 데이터 반환 방식의 2차 고민
마지막으로는 이전 글에서 작성했던 원칙 (id 반환, 데이터 반환 방식 사용 시점)을 전면 수정한 일이 있었습니다.
이전 글의 회원 정보 등록/수정을 할 때에는 아래처럼 닉네임, 신체 정보, 운동 정보, 선호 피트니스/스포츠 등에 대한 정보를 한꺼번에 업로드할 수도 있고, 일부분 (ex: 닉네임 & 신체 정보만)만 업로드할 수 있었습니다.
// 회원 정보 등록, 수정에서 사용되는 JSON 포맷
{
"nickname": "test",
"physicalProfile": {
"birth": "2000.10.10",
"gender": "남성",
"weight": 67.2,
"height": 171.2
},
"preferSports": ["테니스", "탁구"],
"preferFitness": ["벤치프레스", "레그컬"],
"exerciseProfile": {
"level": "입문자",
"goal": "근비대",
"experience": "처음",
"frequency": "매일"
}
}
이때 응답을 할 때 데이터를 모두 반환을 한다면, 조인 과정이 들어가서 (신체 정보, 선호 피트니스/스포츠, 운동 정보) 좋지 않을 것 같다는 생각을 했었는데요, 애초에 처음부터 API를 쪼개놓는다면 (조인 없이) 데이터를 모두 반환하는 방식을 쓸 수 있지 않을까라는 생각이 추가로 들어 API를 쪼개기로 하였습니다.
API를 쪼개놓으니 회원이 다루고자 하는 데이터에 대한 API에만 접근할 수 있도록 할 수 있어 API의 명확성을 높일 수 있다고 생각합니다.
그래서 아래처럼 분할하였습니다.
- 닉네임 수정 API
- 신체 정보 등록 API, 수정 API
- 선호 스포츠 등록 API, 수정 API
- 선호 피트니스 등록 API, 수정 API
- 운동 정보 등록 API, 수정 API
id 반환 방식과 데이터 반환 방식의 최종 결론
id 반환 방식과 데이터 반환 방식에 대한 기준을 모호하게 알게 되는 것 같아, 확실하게 아래로 새롭게 정립하였습니다.
id 반환 방식 (201 Created + Location header에 id 반환 + response body는 사용 X)
- 순차적으로 여러 개로 저장되는 데이터를 다루는 경우 (ex: 게시글)
- 데이터의 생성 API를 나타내면서 응답 데이터가 크게 필요 없다고 판단되는 경우
- 별도의 복잡한 비즈니스 로직이 필요 없는 경우
- 생성이 아닌 수정 등에 대해서는 위 3가지에 해당되더라도 데이터 반환 방식이 적합 - 어떤 값이 수정되어 반영되었는지 나타내는 용도로 쓰일 수 있기 때문
데이터 반환 방식 (생성한 모델의 데이터를 전부 반환하거나 DTO 이용, 또는 다른 모델과 조인)
- 클라이언트가 알아야 할 비즈니스 로직이 처리된 경우
- 데이터의 규모가 크지 않은 경우 ("크기"에 대한 것은 프로젝트에 따라 논의 필요)
- 다른 모델과 조인해서 정보를 표시하는 방법은 최대한 지양, 상태 코드만 나타낸 뒤 조회 API를 이용하도록 고려
- 수정 API에 적합 - 데이터가 어떻게 반영되었는지 즉각 판별할 수 있음
결론
이렇게 API 설계에 대한 고민을 마쳤습니다. 다음 글에서는 이전에 말씀드린 것처럼 원래 작성 예정이었던 DB 설계 시의 고민점에 대해 공유드리겠습니다.
'✨ 프로젝트 > EatToFit [F-Lab]' 카테고리의 다른 글
| [EatToFit] 매개변수가 매우 많을 때에는 도메인 생성 로직을 어떻게 작성해야 할까? (feat. 빌더 패턴, DDD) (5) | 2024.10.30 |
|---|---|
| [EatToFit] DB 설계 과정에서의 고민 (5) | 2024.09.15 |
| [EatToFit] API 설계 과정에서의 고민 (1) (3) | 2024.08.09 |
| [EatToFit] 프로젝트 아이디어 소개 (0) | 2024.08.05 |



